
Transaction and Concurrency Control in DBMS
By BYJU'S Exam Prep
Updated on: September 25th, 2023

Transactions and Concurrency Control is a very important topic from the DBMS subject for all the computer science exams such as GATE CSE, PSU’s & NEILIT exams. These exams aim to test your understanding of a particular deep-level computer science and engineering subject. A simple trick to crack GATE CS is understanding the concept of all the subjects and preparing GATE CSE study notes.
In this article, we have provided you with the free study material for Transactions and Concurrency Control, which is crucial for any GATE CS aspirant. The links below allow you to download the Transactions and Concurrency Control PDF for GATE and other Computer Science exams.
Download Formulas for GATE Computer Science Engineering – Programming & Data Structures
Table of content
-
1.
What is a Transaction?

-
2.
Transaction States
-
3.
What is Concurrency Control?
-
4.
Need for Concurrency Control
-
5.
What is the Schedule in Transaction and Concurrency Control Protocol in DBMS?
-
6.
Classification of Schedules Based on Serializability
-
7.
Concurrency Control with Locking
-
8.
Purpose of Concurrency Control with Locking
-
9.
Variations of the Two-phase Locking (2PL) Technique
What is a Transaction?
A sequence of many actions is considered one atomic unit of work. A transaction is a collection of operations involving data items in a database. A DBMS must ensure four important transaction properties to maintain data in the face of concurrent access and system failures, that is ACID properties.

Atomicity
Atomicity requires that each transaction is all or nothing. If one part of the transaction fails, the entire transaction fails, and the database state is left unchanged.
Consistency
If each transaction is consistent and the database starts as consistent, it ends up as consistent.
Isolation
The execution of one transaction is isolated from that of another transaction. It ensures that concurrent transaction execution results in a system state that would be obtained if the transaction were executed serially, i.e., one after the other.
Durability
Durability means that once a transaction has been committed, it will remain even in the event of power loss, crashes, or errors. For instance, once a group of SQL statements executes in a relational database, the results need to be stored permanently.
Transaction States
The states through which a transaction passes during its lifetime. These are the states that describe the current state of the transaction and how we will proceed with the processing. These states govern the rules determining whether the transaction will commit or abort.
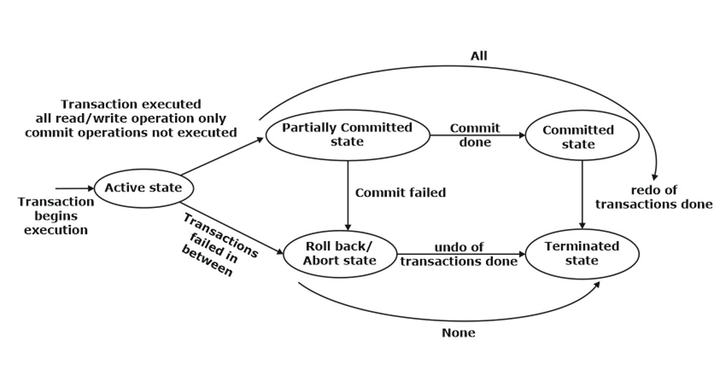
Active state
A transaction will be called in an active state if its instructions are executed. This
is because all the changes made by this transaction are now stored in the buffer
in the main memory.
Partially committed state
After the last instruction of a transaction has been executed, it enters this partially
committed state. After entering the state, the transaction is said to be partially
committed because it has not performed the commit operation. However, the
transaction is not considered fully committed because all the transaction changes
are still stored in the buffer in the main memory.
Committed state
After all the changes executed by the transaction have been committed and
stored successfully in the database, it enters into a state called the committed
state. Now, the transaction is considered fully committed.
Abort state (Rollback state)
When a transaction is being executed in the active state or partially committed
state, and some failure occurs, due to which it becomes impossible to continue
the execution, it enters into a failed state.
After the transaction is failed and enters into a failed state, all the changes
made by this transaction have to be undone. To undo the changes made by this
transaction, it becomes necessary to roll back all the transaction operations.
After the transaction fully rolls back, it enters into an aborted state.
Terminated state
When a transaction successfully performs the redo operation in case of a committed
transaction or performs the undo operation in case of a failed transaction, it is
said to be in the terminated state. Therefore, to maintain the correctness of
the databases, it will execute all the transactions successfully, or none of the
transactions will be executed in case any failure occurs.
What is Concurrency Control?
The process of managing the simultaneous execution of transactions in a shared database is known as concurrency control. Concurrency control ensures that correct results for concurrent operations are generated while getting those results as quickly as possible.
Need for Concurrency Control
Simultaneous execution of transactions over a shared database can create several data integrity and consistency problems.
Lost Update
This problem occurs when two transactions that access the same database items have their operations interleaved in a way that makes the value of some database items incorrect.
Read also: Database Notes for GATE CS.
Dirty Read Problems
This problem occurs when one transaction changes the value while the other reads the value before committing or rolling back by the first transaction.
Inconsistent Retrievals
This problem occurs when a transaction accesses data before and after another transaction(s) finishes working with such data.
We need concurrence control, when
- The amount of data is sufficiently great that at any time, only a fraction of the data can be in primary memory, and the rest should be swapped from secondary memory as needed.
- Even if the entire database can be present in primary memory, there may be multiple processes.
What is the Schedule in Transaction and Concurrency Control Protocol in DBMS?
A schedule (or history) is a model to describe the execution of transactions running in the system. When multiple transactions are executed concurrently in an interleaved fashion, then the order of execution of operations from the various transactions is known as a schedule, or we can say that a schedule is a sequence of reading, writing, aborting, and committing operations from a set of transactions.
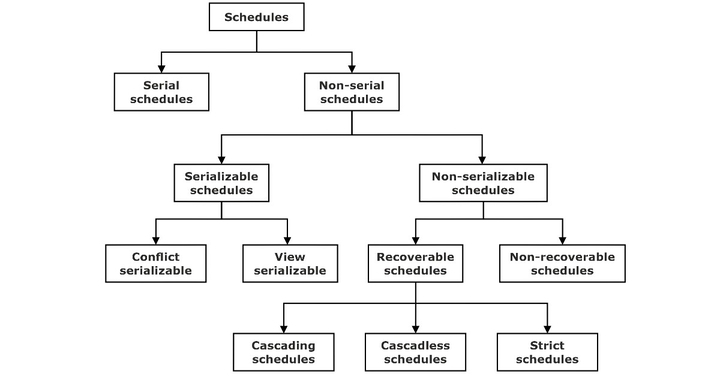
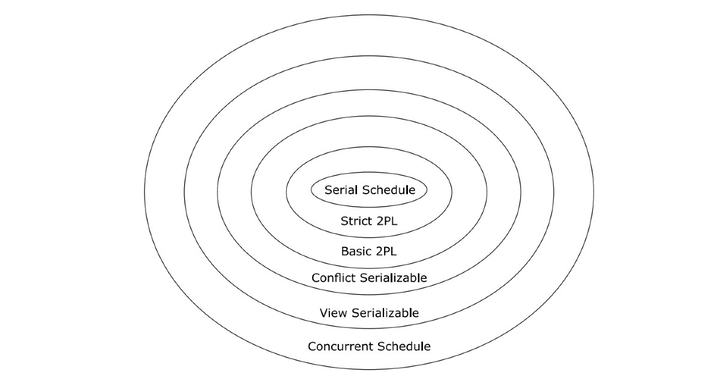
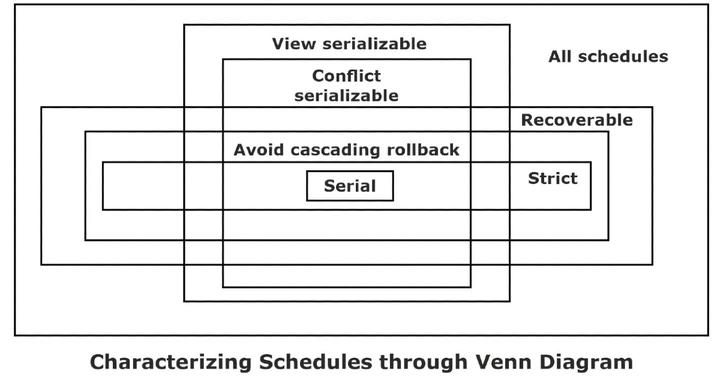
Classification of Schedules Based on Serializability
A schedule in which the different transactions are not interleaved (i.e., transactions are executed from start to finish one by one). Serial schedules and concurrent schedules are further classified as shown in the
classification diagram:
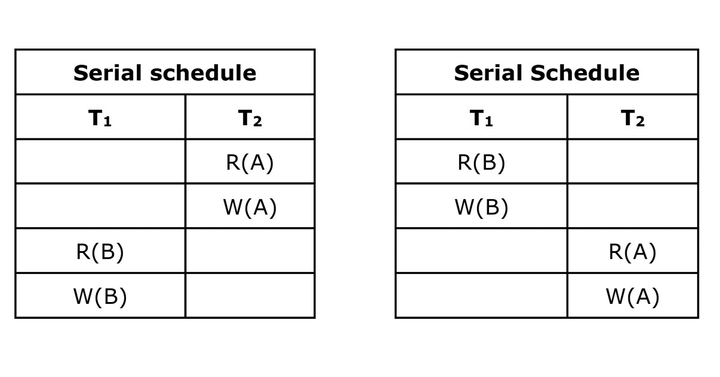
Serial Schedule
A schedule in which a new transaction is allowed to begin only after completing the previous transaction. No middle interleaving is allowed.
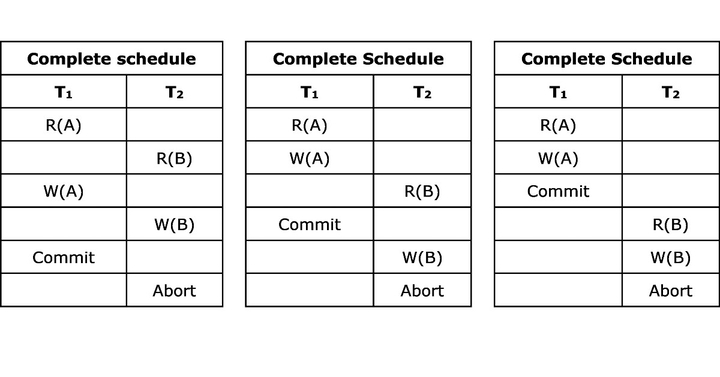
Complete Schedule: A schedule that contains either a commit or an abort action for each transaction. Consequently, a complete schedule will not contain any active transactions at the end of the schedule.
 Non-serial Schedules: Non-serial schedules are interleaved schedules that improve the system’s performance (i.e., throughput and response time). But concurrency or interleaving operations in schedules might lead the database to an inconsistent state. We need to seek to identify schedules that are:
Non-serial Schedules: Non-serial schedules are interleaved schedules that improve the system’s performance (i.e., throughput and response time). But concurrency or interleaving operations in schedules might lead the database to an inconsistent state. We need to seek to identify schedules that are:
- As fast as interleaved schedules.
- As consistent as serial schedules.
Conflicting Operations
When two or more transactions in a non-serial schedule execute concurrently, some conflicting operations may occur. Two operations are said to be conflicting if they satisfy the following conditions.
- The operations belong to different transactions.
- At least one of the operations is a write operation.
- The operations access the same object or item.
The following set of operations is conflicting.
While the following sets of operations are not conflicting
SerializableSchedule
A schedule S of n transactions is serializable if it is equivalent to some serial schedule of the same n transactions.
A non-serial schedule S is serializable is equivalent to saying that it is correct because it is equivalent to a serial schedule. There are two types of serializable schedules.
- Conflict serializable schedule
- View serializable schedule
Conflict Serializable Schedule
When the schedule (S) is conflict equivalent to some serial schedule (Sï), that schedule is called a conflict serializable schedule. In such a case, we can reorder the non-conflicting operations in S until we form the equivalent serial schedule S’.
Conflict Equivalence: The schedules S1 and S2 are said to be conflict equivalent if the following conditions are satisfied:
- Both schedules S1 and S2 involve the same set of transactions (including the ordering of operations within each transaction).
- The order of each pair of conflicting actions in S1 and S2 is the same.
Testing for Conflict Serializability of a Schedule: A simple algorithm can be used to test a schedule for conflict serializability. This algorithm constructs a precedence graph (or serialization graph), a directed graph. A precedence graph for a schedule S contains
- A node for each committed transaction in S.
- An edge from Ti to Tj if an action of Ti precedes and conflicts with one of Tj’s operations.
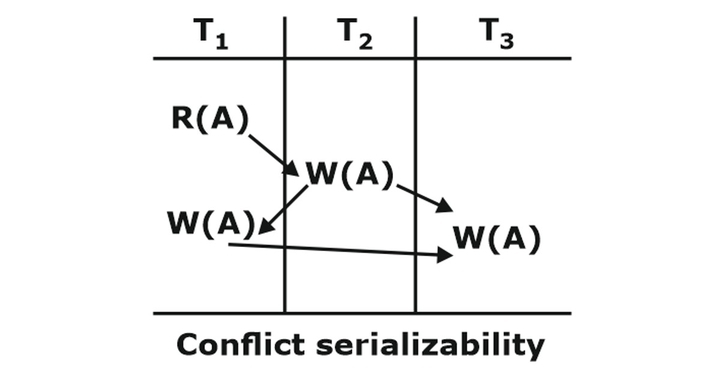
A schedule S is a conflict serializable if and only if its precedence graphs are acyclic.
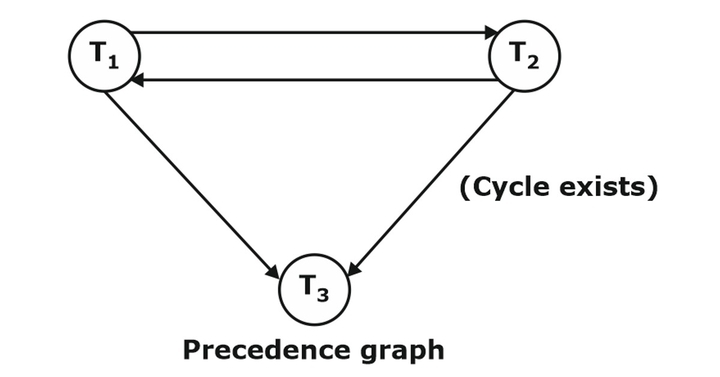
Note: The above example of schedule does not conflict serializable schedule.
View Serializable Schedule
A schedule is viewed as serializable if it is equivalent to some serial schedule. Conflict serializable ï View serializable, but not vice-versa.
View Equivalence: Two schedules S1 and S2, are view equivalent,
- Ti reads the initial value of database object A in schedule S1 then Ti also reads the initial value of database object A in schedule S2.
- Ti reads the value of A written by Tj in schedule S1 then Ti also reads the value of A written by Tj in schedule S2.
- Ti writes the final value of A in schedule Sl then Ti also writes the final value of A in S2.
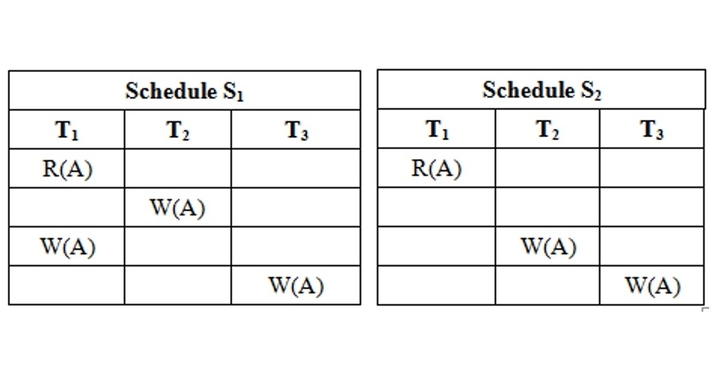
In the above example, both schedules S1 and S2 are view equivalent. So, they view serializable schedules. But the S1 schedule does not conflict serializable schedule, and S2 is not conflicted serializable schedule because the cycle is not formed.
Recoverable Schedule
Once a transaction T is committed, rolling back T should never be necessary. The schedules under this criteria are called recoverable schedules, and those that do not are called non-recoverable. A schedule S is recoverable if no transaction T in S commits until all transactions Tthat have written an item T have committed.
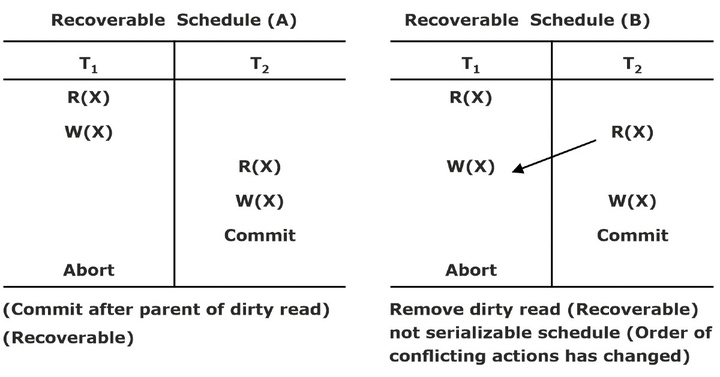
Cascade-less Schedule
These schedules avoid cascading rollbacks. Even if a schedule is recoverable to recover correctly from the failure of transaction Ti, we may have to roll back several transactions. This phenomenon in which a single transaction failure leads to a series of transaction rollbacks is called cascading rollbacks.
Cascading rollback is undesirable since it leads to undoing a significant amount of work. It is desirable to restrict the schedules to those where cascading rollback cannot occur. Such schedules are called cascade-less schedules.
Cascade-less Schedule
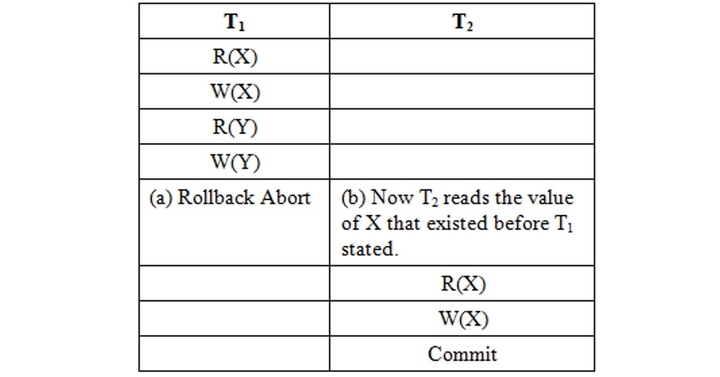
Strict Schedule
A schedule is strict,
- If overriding uncommitted data is not allowed.
- Formally, if it satisfies the following conditions
- Tj reads a data item X after Ti has terminated (aborted or committed).
- Tj writes a data item X after Ti has terminated (aborted or committed).
Concurrency Control with Locking
If concurrency control with the locking technique is used, then locks prevent multiple transactions from accessing the items concurrently.
- Access on data only if TA ‘has lock’ on data.
- Transactions request and release locks.
- The schedule allows or differs operations based on the lock table.
Lock: A lock is a variable associated with a data item that describes the item’s status concerning possible operations that can be applied to it. (e.g., read lock, write lock). Locks are used to synchronizing access by concurrent transactions to the database items. There is one lock per database item.
Problems Arising with Locks: There are two problems that are possible when using locks to control the concurrency among transactions.
- Deadlock: Two or more competing transactions are waiting for each other to complete to obtain a missing lock.
- Starvation: A transaction is continually denying access to a given data item.
Purpose of Concurrency Control with Locking
- To enforce isolation among conflicting transactions.
- To preserve database consistency.
- To resolve read-write, write-read, and write-write conflicts.
Locking is an operation that secures permission to read and permission to write a data item.
Lock (X): Data item X is locked on behalf of the requesting transaction.
Unlocking is an operation that removes these permissions from the data item.
Unlock (X): Data item X is available for all other transactions.
Types of Locks: The two types of Locks are given below
Binary Locks: A binary lock has two states: Locked/Unlocked. If a database item X is locked, then X cannot be accessed by any other database operation.
Shared/Exclusive Locks (Read/Write Locks): There are three states:- Read locked / Writelocked / Unlocked. Several transactions can access the same item X for reading (shared lock); however, if any transactions want to write item X, the transaction must acquire an exclusive lock on the item.
Guaranteeing Serializability by Two-phase Locking
A transaction is said to follow the two-phase locking protocol if all locking operations precede the first unlock operation in the transaction.
Such a transaction can be divided into two phases:
- Expanding or Growing Phase During which new locks on items can be acquired, but none can be released.
- Shrinking Phase During which existing locks can be released, but no new locks can be acquired.
Variations of the Two-phase Locking (2PL) Technique
- Basic 2PL (2 Phase Locking) Transaction locks data items incrementally. This may cause the problem of deadlock.
- Conservative 2PL (Static 2PL) Prevents deadlock by locking all desired data items before the transaction begins execution. However, it is difficult to use in practice because of the need to predeclare the read-set and write-set, which is impossible in most situations.
- Strict 2PL A stricter version of the basic algorithm, where the write lock is unlocked after a transaction terminates (commits or aborts and rolled back). Hence, no other transaction can read or write an item written by the transaction.
- Rigorous 2PL Strict 2PL is not deadlock-free. A more restrictive variation of strict 2PL is rigorous 2PL, which guarantees a strict schedule. In this variation, a transaction does not release any of its locks (exclusive or shared) until after it commits or aborts.
What is Deadlock?
A deadlock is a condition in which two or more transactions are waiting for each other deadlock (T1 and T2). An example is given below.

Deadlock Prevention: A transaction locks all data items; it refers to before it begins execution. This way of locking prevents deadlock since a transaction never waits for a data item. Conservative two-phase locking uses this approach.
Deadlock Detection and Resolution: In this approach, deadlocks are allowed to happen. The scheduler maintains a wait-for-graph for detecting cycles. If a cycle exists, one transaction involved is selected (victim) and rolled back.
- A wait-for-graph is created using the lock table. As soon as a transaction is blocked, it is added to the graph.
- When a chain like Ti waits for Tj, Tj waits for TK, and Tk waits for Ti or Tj, this creates a cycle. One of the transactions of the cycle is selected and rolled back.
Deadlock Avoidance: There are many variations of the two-phase locking algorithm. Some avoid deadlock by not letting the cycle to complete. This is because as soon as the algorithm discovers that blocking a translation is likely to create a cycle, it rolls back the transaction.
The following schemes use transaction timestamps for the sake of deadlock avoidance.
Wait-die scheme (Non-preemptive): Older transactions may wait for the younger ones to release data items. Younger transactions never wait for older ones; they are rolled back instead. A transaction may die several times before acquiring the needed data item.
Wound-wait scheme (Preemptive): Older transaction bounds (forces rollback) of the younger transaction instead of waiting for it. Younger transactions may wait for older ones. May be fewer rollbacks than the wait-die scheme.
Starvation: Starvation occurs when a particular transaction consistently waits or restarted and never gets a chance to proceed further. In a deadlock resolution scheme, it is possible that the same transaction may consistently be selected as a victim and rolled back.
Time-stamp-Based Concurrency Control Algorithm: This is a different approach that guarantees serializability and involves using transaction time-stamps to order transaction execution for an equivalent serial schedule.
Time-stamp: A time-stamp is a unique identifier created by the DBMS to identify a transaction.
- Time-stamp is a monotonically increasing variable (integer) indicating the age of an operation or a transaction.
- A larger time-stamp value indicates a more recent event or operation.
Starvation versus Deadlock
|
Starvation |
Deadlock |
|
Starvation happens if the same transaction is always chosen as the victim. |
A deadlock is a condition in which two or more transactions are waiting for each other. |
|
It occurs if the waiting scheme for locked items is unfair, prioritizing some transactions over others. |
A situation where two or more transactions cannot proceed because each is waiting for one of the others to do something. |
|
Starvation is also known as a lived lock. |
Deadlock is also known as circular waiting. |
|
Switch priorities so that every threat has a chance to have high priority. |
Use FIFO order among competing requests. |
|
It is a situation where transactions are waiting for each other. |
Acquire locks are in a predefined order. |
|
It means that the transaction goes in a state where the transaction never progresses. |
Acquire locks at one before starting |
The algorithm associates each database item X with two Time Stamp (TS) values
Read_TS(X): The read timestamp of item X; this is the largest time-stamp among all the time-stamps of transactions that have successfully read item X.
Write_TS (X): The write time-stamp of item X; this is the largest time-stamp among all the time-stamps of transactions that have successfully written item X.
There are two Time-Stamp-based Concurrency Control Algorithms.
Basic Time-stamp Ordering (TO): Whenever some transaction T tries to issue an R(X) or a W(X) operation, the basic time-stamp ordering algorithm compares the time-stamp of T with read_TS (X) and write_TS (X) to ensure that the time-stamp order of transaction execution is not violated. If this order is violated, then transaction T is aborted. If T is aborted and rolled back, any transaction T1 that may have used a value written by T must also be rolled back. Similarly, any transaction T2 that may have used a value written by T1 must also be rolled back. This effect is known as cascading rollback. The concurrency control algorithm must check whether conflicting operations violate the time-stamp ordering in the following two cases.
Transaction T issues a W(X) operation: If read_TS (X) > TS (T) or if write_TS (X) > TS (T), then a younger transaction has already read the data item, so abort and roll back T and reject the operation.
If the condition in the above part does not exist, then execute W(X) of T and set write_TS (X) to TS (T).
Transaction T issues a R (X) operation: If write_TS (X) > TS (T), then a younger transaction has already been written to the data item, so abort and roll back T and reject the operation.
If write_TS (X) ï TS (T), then execute R(X) of T and set read_TS (T) to the larger of TS (T) and the current read_TS (X).
Strict Time-stamp Ordering (TO): A variation of basic time-stamp ordering, called strict time-stamp ordering, ensures that the schedules are both strict (for easy recoverability) and serializable (conflict).
Transaction T issues a W(X) operation: If TS (T) > read_TS (X), then delay T until the transaction Tï that wrote or read X has terminated (committed or aborted).
Transaction T issues a R(X) operation: If TS (T) > write_TS (X), then delay T until the transaction T’ that wrote or read X has terminated (committed or aborted).
Thomas’s Write Rule:
- If read_TS (X) > TS (T), then abort and roll back T and reject the operation.
- If write_TS (X) > TS (T), then just ignore the write operation and continue execution.
- This is because the most recent writes count in the case of two consecutive writes. If the conditions given in (i) and (ii) above do not occur, then execute W(X) of T and set write_TS (X) to TS(T).
Multiversion Concurrency Control Techniques: This approach maintains several versions of a data item and allocates the right version to a read operation of a transaction. Thus, unlike other mechanisms, a read operation in this mechanism is never rejected.
The side effect is thatsignificantly more storage is required to maintain multiple versions.
Validation-Based Concurrency Control Protocol: Transaction Ti is executed in three phases.
- Read, and Execution Phase Transaction Ti writes only to temporary local variables.
- Validation Phase Transaction Ti performs a validation test to determine if local variables can be written without violating serializability.
- Write Phase If Ti is validated, the updates are applied to the database, otherwise, Ti is rolled back.
The above three phases of concurrently executing transactions can be interleaved, but each transaction must go through the three phases in that order.
Each transaction Ti has three time stamps:
- Start (Ti) The time when Ti started its execution.
- Validation (Ti) The time when Ti entered its validation phase.
- Finish (Ti) The time when Ti finished its write phase.
Serializability order is determined by the time-stamp given at validation time to increase concurrency. Thus, TS (Ti) is given the value of validation (Ti). For all Ti with TS (Ti) < TS (Tj), either one of the following conditions holds:
- Finish (Ti) < Start (Tj)
- Start (Tj) < Finish (Ti) < Validation (Tj),
And the set of data items written by Ti does not intersect with the set of data items read by Tj. Then, validation succeeds, and Tj can be committed. Otherwise, validation fails, and Tj is aborted.
The topic-wise study notes are also useful for preparing for upcoming exams like GATE CSE/ BARC / NIELIT and other important upcoming competitive exams.



