
Routing Algorithms in Computer Networs – Distance Vector, Link State
By BYJU'S Exam Prep
Updated on: September 25th, 2023

Data is converted into packets in computer networks before being transferred from source to destination. The network layer chooses the best path for data packet transmission. The network layers provide a routing protocol, which is a routing algorithm that determines the best and shortest path for transmitting data from source to destination.
Routing algorithms are an essential component of computer networks. Without them, data cannot flow between different parts of the network. This article will look at the various types of routing algorithms and how they work.
Table of content
What is Routing Algorithm?
A routing algorithm is a routing protocol determined by the network layer for transmitting data packets from source to destination. This algorithm determines the best or least-cost path for data transmission from sender/source to receiver/destination.
The network layer performs operations that effectively and efficiently regulate internet traffic. In computer networks, this is known as a routing algorithm. It is used to determine the best path or route mathematically.
Types of Routing Algorithms
Algorithms may be dynamic, where the routers make decisions based on information they gather, and the routes change over time adaptively. Routing Algorithms can be classified based on the following types.
- Static or Dynamic Routing
- Distributed or Centralized
- Single-path or Multi-path
- Flat or Hierarchical
- Intra Domain or Inter-Domain
- link State or Distance Vector
Further routing can be grouped into two categories: Non-adaptive routing and Adaptive routing.
Non-adaptive Routing
Once the pathway to the destination has been selected, the router sends all packets for that destination along that one route. The routing decisions are not made based on the condition or topology of the network.
Examples: Centralized, Isolated, and Distributed Algorithms
Adaptive Routing
A router may select a new route for each packet (even packets belonging to the same transmission) in response to changes in the condition and topology of the networks.
Examples: Flooding and Random Walk.
Routing Algorithms Examples
Shortest Path Routing
- Links between routers have a cost associated with them. It could be a function of distance, bandwidth, average traffic, communication cost, mean queue length, measured delay, router processing speed, etc.
- The shortest path algorithm finds the least expensive path through the network based on the cost function.
- Examples: Dijkstra’s algorithm
Distance Vector Routing
Each router periodically shares knowledge about the entire network with its neighbours in this routing scheme. Each router has a table with information about the network. These tables are updated by exchanging information with the immediate neighbours. It is also known as Belman-Ford or Ford-Fulkerson Algorithm. It is used in the original ARPANET and the Internet as RIP.
- Neighbouring nodes in the subnet exchange their tables periodically to update each other on the state of the subnet (which makes this a dynamic algorithm). If a neighbour claims to have a path to a node shorter than your path, you start using that neighbour as the route to that node.
- Distance vector protocols (a vector contains both distance and direction), such as RIP, determine the path to remote networks using hop count as the metric. A hop count is defined as the number of times a packet needs to pass through a router to reach a remote destination.
- For IP RIP, the maximum hop is 15. Therefore, a hop count of 16 indicates an unreachable network. Two versions of RIP exist version 1 and version 2.
- IGRP is another example of a distance vector protocol with a higher hop count of 255 hops.
- Periodic updates are sent at a set interval. For IP RIP, this interval is 30 seconds.
- Updates are sent to the broadcast address 255.255.255.255. Only devices running routing algorithms listen to these updates.
- When an update is sent, the entire routing table is sent.
Link State Routing
The following sequence of steps can be executed in the Link State Routing. This advertising is a short pack called a Link State Packet (LSP). OSPF (Open shortest path first) and IS-IS are examples of Link state routing. Link State Packet(LSP) contains the following information:
- The ID of the node that created the LSP;
- A list of directly connected neighbours of that node, with the cost of the link to each one;
- A sequence number;
- A time to live(TTL) for this packet.
When a router floods the network with information about its neighbourhood, it is said to be advertising.
- Discover your neighbours
- Measure delay to your neighbours
- Bundle all the information about your neighbours together
- Send this information to all other routers in the subnet
- Compute the shortest path to every router with the information you receive
- Each router finds its own shortest path to the other routers using Dijkstra’s algorithm.
In link-state routing, each router shares its knowledge of its neighbourhood with all routers in the network. Link-state protocols implement an algorithm called the shortest path first (SPF, also known as Dijkstra’s Algorithm) to determine the path to a remote destination. There is no hop-count limit. (For an IP datagram, the maximum time to live ensures that loops are avoided.).Only when changes occur, It sends all summary information every 30 minutes by default. Only devices running routing algorithms listen to these updates. Updates are sent to a multicast address. As a result, updates are faster, and convergence times are reduced. Higher CPU and memory requirements to maintain link-state databases. Link-state protocols maintain three separate tables.
- Neighbour table: It contains a list of all neighbours and the interface to which each neighbour is connected. Neighbours are formed by sending Hello packets.
- Topology table (Link- State table): It contains a map of all links within an area, including each link’s status.
- Routing table: It contains the best routes to each particular destination
Flooding Algorithm
It is a non-adaptive algorithm or static algorithm. When a router receives a packet, it sends a copy of the packet out on each line (except the one on which it arrived). Each router decrements a hop count contained in the packet header to prevent looping forever. As soon as the hop count decrements to zero, the router discards the packet.
Flow-Based Routing Algorithm
- It is a non-adaptive routing algorithm.
- It takes into account both the topology and the load in this routing algorithm;
- We can estimate the flow between all pairs of routers.
- You can compute the mean packet delays using queuing theory from the known average amount of traffic and the average length of a packet.
- Flow-based routing then seeks to find a routing table to minimize the average packet delay through the subnet.
- Given the line capacity and the flow, we can determine the delay. It needs to use the formula for delay time T.
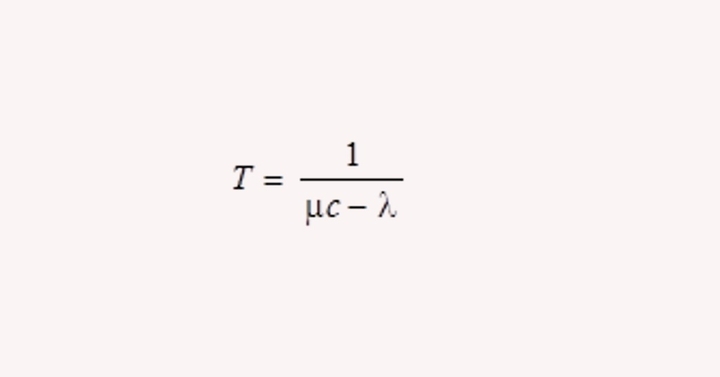
- Where, μ = Mean number of arrivals in packet/sec, 1/μ = The mean packet size in the bits, and c = Line capacity (bits/s).
Candidates can also practice 110+ Mock tests for exams like GATE and NIELIT with BYJU’S Exam Prep Test Series; check the following link
Click Here to Avail GATE CSE Test Series!
Thanks
#DreamStriveSucceed



